Une documentation toujours en retard
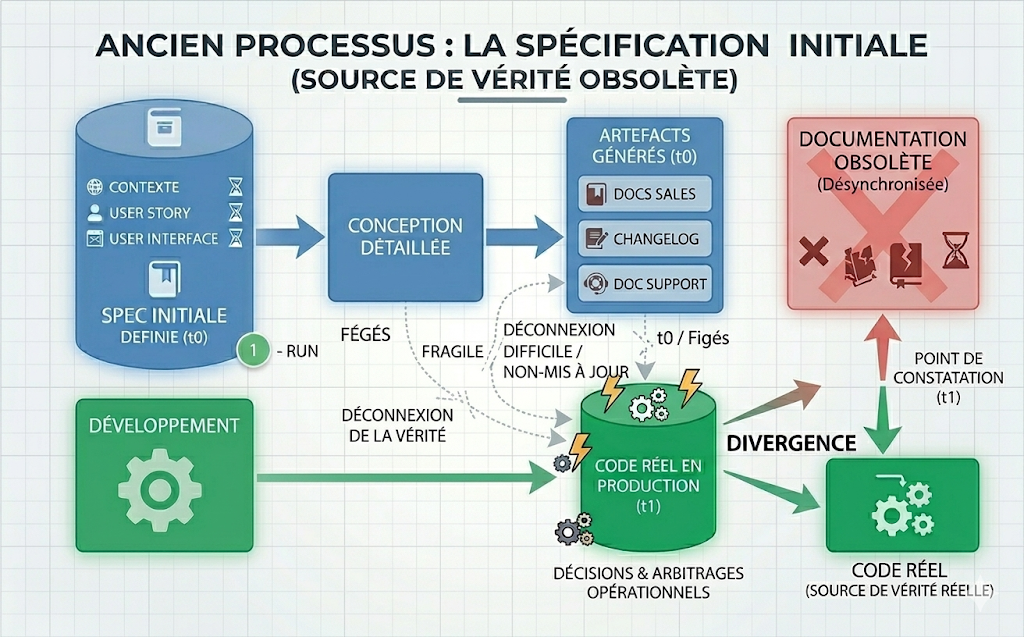
Nous l'avons tous vécu : un bug apparaît, ou une évolution fonctionnelle doit être traitée. Le premier réflexe consiste à consulter la documentation. Et, bien souvent, celle-ci n'est plus à jour.
En réalité, nous savons presque d'avance qu'elle ne le sera pas. Le schéma est connu : une documentation est produite, transmise avec la spécification, puis le développement commence. En cours de route, des questions apparaissent, des arbitrages sont rendus, certains points évoluent, et les développeurs prennent parfois des décisions sans revenir systématiquement vers le product manager. C'est normal. Sinon, le travail avancerait au rythme d'une validation permanente. Le résultat, en revanche, est toujours le même : la documentation et le code finissent par diverger.
Cette divergence tient aussi à une contrainte très simple. À chaque modification, même mineure, personne n'a réellement le temps de repartir à la recherche de la bonne spécification, de la bonne maquette, du bon document support ou du bon changelog pour tout remettre à jour. Nous travaillons autour d'un produit vivant, qui évolue en continu. Dans ce contexte, maintenir manuellement l'ensemble des artefacts devient vite trop coûteux par rapport au temps disponible.
Plus le temps passe, plus le problème s'aggrave. Aujourd'hui, une fonctionnalité n'est plus conçue une fois pour toutes : elle est ajustée, enrichie, corrigée, parfois pendant des mois ou des années. Dans ces conditions, il est peu réaliste d'espérer maintenir parfaitement synchronisés la spécification initiale, les échanges projet, le changelog, la documentation de support, la documentation commerciale et les maquettes.
Le code comme source de vérité
Le véritable livrable, au fond, c'est le code. Ce n'est peut-être pas la formule officielle, mais c'est bien lui qui décrit l'état réel du produit. Le reste ne fait que tenter de le suivre. À cet égard, l'expression "Code is Law" reste particulièrement juste : https://framablog.org/2010/05/22/code-is-law-lessig/
Pendant longtemps, cette situation était inévitable. La documentation en langage naturel constituait la moins mauvaise solution, notamment parce que la plupart des product managers ne travaillent pas directement dans le code. Il fallait donc une couche intermédiaire, compréhensible par tous, exploitable en réunion, partageable avec les équipes, et utilisable sans compétence technique particulière.
Ce que l'IA change
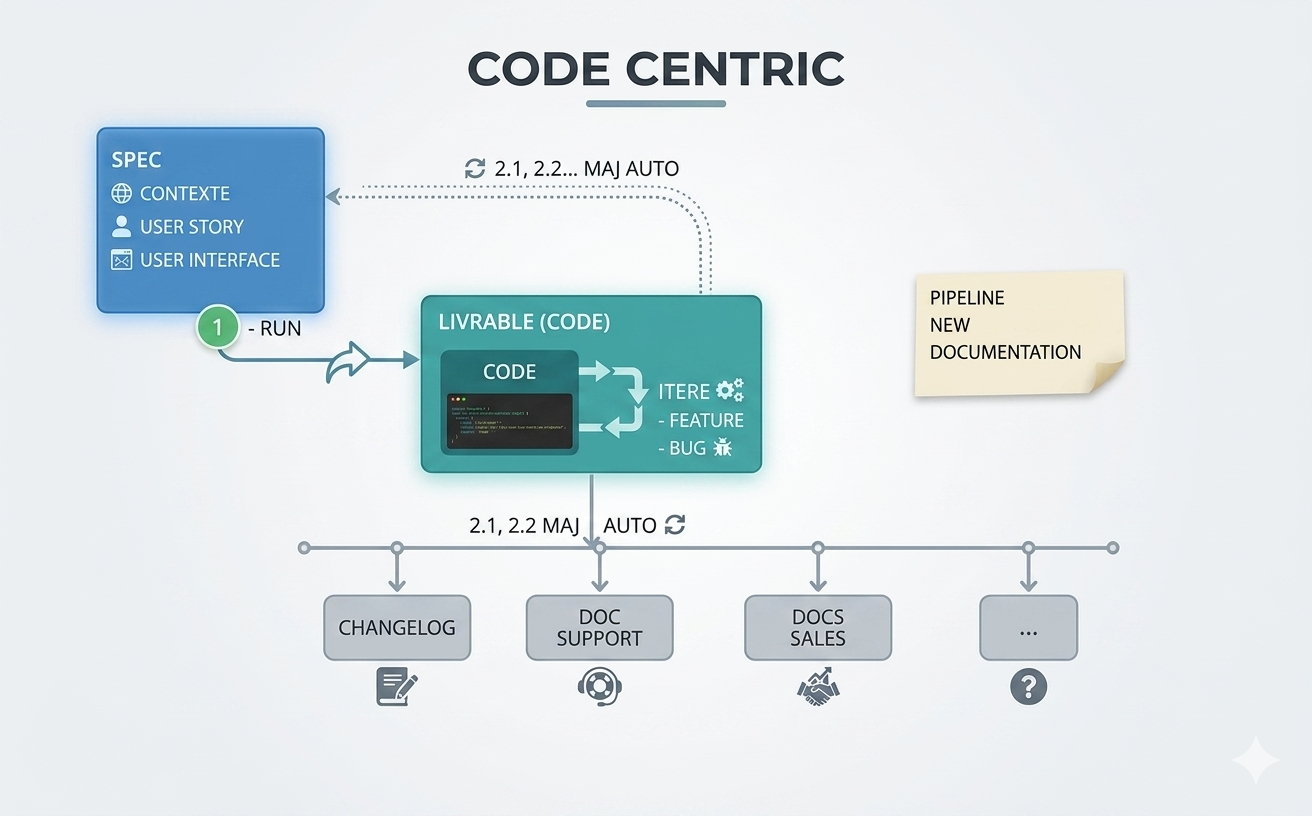
L'IA change désormais cette équation. Lorsque le code est suffisamment propre et documenté, il devient possible d'en faire une source exploitable pour reconstruire ou mettre à jour d'autres livrables. On peut, par exemple, repartir du code réel pour remettre à jour une documentation de support après une livraison, générer un changelog plus fiable, ou reconstituer une spécification fonctionnelle à partir de l'état actuel du produit plutôt qu'à partir d'un document ancien.
Le code ne constitue plus seulement le livrable final : il devient l'élément central, la source de vérité à partir de laquelle gravitent et se reconstruisent les autres artefacts du produit, dans une logique véritablement code centric.
La question de la culture technique
Mais cela ouvre une autre question : comment un product manager non technique peut-il tirer parti de cette possibilité ?
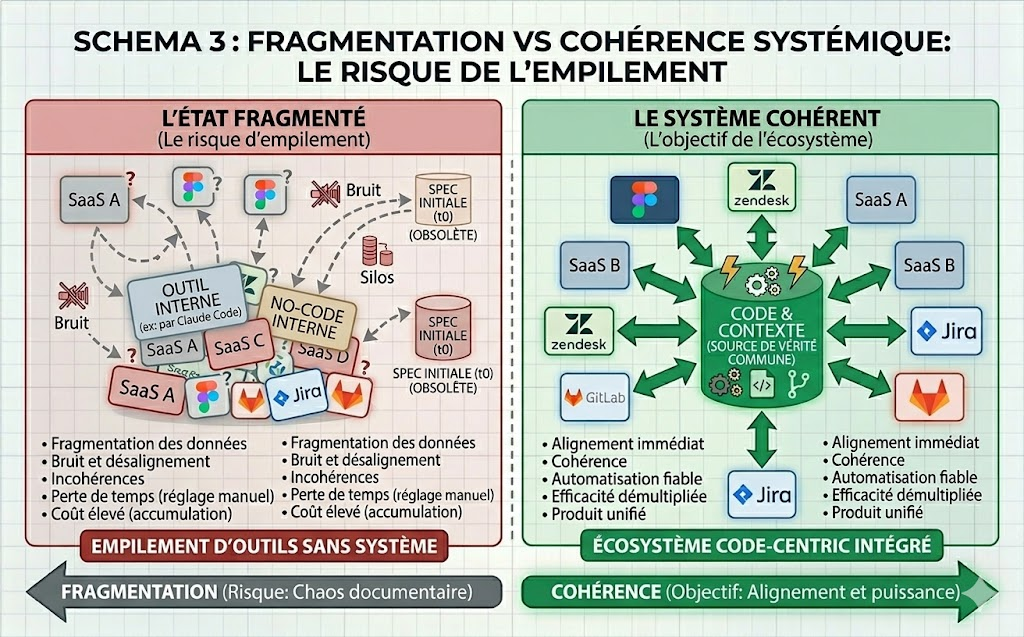
Les outils actuels sont puissants, mais ils ne s'utilisent pas sans discernement. Ils peuvent aider à produire vite, à automatiser certaines tâches et à générer des briques utiles. En revanche, dès que l'on touche à l'architecture, à la cohérence d'ensemble ou à la maintenabilité, leurs limites apparaissent rapidement. Sans un minimum de culture technique, le risque est de multiplier les petits outils efficaces localement mais mal articulés entre eux. On gagne du temps ici ou là, puis on le reperd ensuite à faire circuler les données, à gérer des incohérences, ou à maintenir un ensemble devenu difficile à comprendre.
L'enjeu n'est donc pas seulement de produire plus vite. Il est de produire dans un cadre cohérent. C'est cette cohérence qui fait la différence entre une accumulation d'outils et un véritable système de travail.
De ce point de vue, il existe sans doute déjà un écart de capacité entre les PM issus d'un parcours technique et ceux qui ne le sont pas. Non pas parce que les uns seraient intrinsèquement meilleurs que les autres, mais parce que les premiers disposent aujourd'hui d'un levier supplémentaire : ils peuvent intervenir plus directement sur la matière même du produit, c'est-à-dire le code, et s'en servir comme base pour générer, contrôler ou challenger d'autres artefacts.
On pourrait objecter que les SaaS intégreront de plus en plus d'agents capables d'automatiser ces tâches. C'est probable, et ce sera un progrès réel. Mais je ne pense pas que cela suffira à effacer la différence. La plupart de ces outils resteront spécialisés.
C'est précisément là que la limite apparaît. Un outil comme Zendesk pourra probablement aider à produire une meilleure documentation de support. Un outil comme Figma restera excellent pour concevoir des écrans. Mais ni l'un ni l'autre n'ont, à eux seuls, une vision complète du produit réel tel qu'il existe dans le code, tel qu'il évolue dans les merge requests, et tel qu'il doit être compris dans son contexte métier.
Aujourd'hui, avec les bons outils, je peux par exemple croiser plusieurs niveaux d'information : le code source, l'historique des évolutions, les merge requests, et les règles métier que j'ai accumulées comme product manager. Cela permet non seulement de générer une documentation plus juste, mais aussi de challenger ce qui existe déjà.
La même logique vaut pour la conception. Aujourd'hui, on dessine une interface dans Figma, puis il faut la développer. Mais si je suis capable de reconstruire un design system à partir du code réel, de le tenir à jour en fonction des évolutions du dépôt, et d'y ajouter les conventions de développement de l'équipe, alors la maquette change de statut. Elle ne devient plus seulement une représentation : elle peut commencer à devenir une première base exploitable par les développeurs front-end.
Autrement dit, la frontière entre conception, implémentation et documentation commence à se réduire. Ce n'est pas seulement une question de productivité. C'est une transformation plus profonde : le code n'est plus simplement l'aboutissement du travail, il devient aussi la matière première à partir de laquelle on peut reconstruire le reste.
Ce que le MCP va changer
Je ne prétends pas que ce modèle soit déjà stabilisé. Dans quelques mois, il sera peut-être en partie dépassé. Le MCP, notamment, peut encore changer l'équilibre. On peut imaginer demain un écosystème dans lequel chaque SaaS disposerait de sa propre couche d'agents, capable de dialoguer avec d'autres systèmes. Figma pourrait, par exemple, récupérer du contexte issu d'un dépôt GitLab, lire les évolutions récentes, comprendre les merge requests pertinentes, et mieux aligner la conception sur la réalité du produit. Nous n'en sommes pas encore entièrement là, mais la direction devient visible.
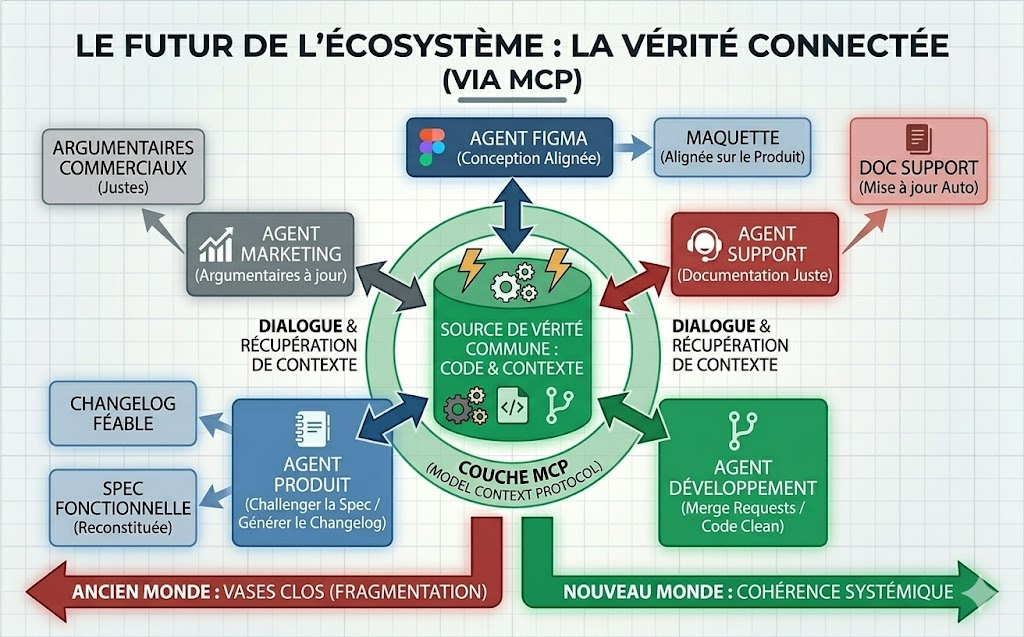
C'est pour cela que le MCP me semble important. De la même manière que les API sont devenues indispensables lorsque les SaaS ont cessé de vivre en vase clos, les MCP pourraient devenir essentiels à mesure que les agents se généralisent. Chaque outil conservera sa spécialité, mais la valeur réelle viendra de sa capacité à dialoguer avec les autres, à récupérer du contexte, et à agir dans un écosystème plus large que son propre périmètre.
La meilleure attitude, à ce stade, est sans doute d'expérimenter sérieusement. Non pour suivre un effet de mode, mais pour comprendre ce qui permet déjà, concrètement, de créer de la valeur. Car le changement en cours n'est pas seulement technologique. Il touche à la nature même des livrables du produit, à leur source de vérité, et à la place du product manager dans leur production.
Pour en savoir plus
Ajouter une mémoire de session comme dans OpenClaw En 8 jours, j'ai compris que le métier de Product Manager allait changer du tout au tout La qualité appartient à ceux qui livrent La question produit doit partir du code source